سلام. امیر پورمند هستم و با قسمت بیستم از ایستگاه هوش مصنوعی در خدمتتون هستم.
تو دو قسمت قبلی، دو بخش از کتاب الگوریتم اصلی رو بازخوانی کردیم. خلاصه این که یادگیری ماشین یک الگوریتم یادگیرنده داره. الگوریتم یادگیرنده، داده ورودی و داده خروجی رو میگیره و الگوریتمی خروجی میده که اون کار رو انجام بده.
مثلاً برای تشخیص اسپم، ورودی میشه ایمیلها و خروجی میشه اونهایی که اسپم هستند. حالا اینها رو به الگوریتم یادگیرنده میدیم و خروجیش میشه یه الگوریتم تشخیص اسپم.
تو بخشهای قبل گفتیم که الگوریتمهای یادگیرنده تعدادشون محدوده. تو این فصل میخوایم به یک سؤال بپردازیم. «آیا میشه با یک الگوریتم یادگیرنده همه چیز رو یاد بگیریم؟»
شنیدن اپیزود
همه اپیزودهای این پادکست تو کانال کست باکس منتشر میشه و البته میتونید از جاهای دیگه هم بشنوید.اینجا هم میتونید فایل صوتی این قسمت رو گوش بدید:
مقدمه
فقط قبل این که شروع کنم بگم که از این قسمت به بعد تو تهیه محتوای پادکست از LLMها هم کمک میگیرم. به نظرم اگر غیر از این باشه، اشتباهه. معنی کمک گرفتن هم این نیست که متن کتاب رو بدم و برام پادکست تولید کنه و بیام عیناً برای شما بگم. این هیچ معنایی نداره.
معنیش اینه که در فرآیند تدوین و فکر کردن به محتوای کتاب و تهیه خلاصه ازش، کلی با LLMها صحبت میکنم. به نظرم برای کتاب خوندن خیلی خوبه. انگار آدم نویسنده کتاب رو کنار خودش داره و با نویسنده گفتگو میکنه.
الگوریتم اصلی
نویسنده بحثش رو با این شروع میکنه که این که الگوریتمهای یادگیرنده یکسان برای کارهای کاملاً متفاوت استفاده میشن. این کاملاً برخلاف روندی هست که در مهندسی نرمافزار داریم. تو مهندسی نرمافزار راهحلهای متفاوت برای مسائل متفاوت داریم. مثلاً یه مرورگر وب با نرمافزار شطرنج با نرمافزار حسابداری یکی نیستند. کد سمت Backend و Frontend و کتابخانههایی که استفاده میکنند و همه چیشون فرق داره.
اما تو یادگیری ماشین، الگوریتمی مثل Naive Bayes (که بعداً توضیح میدم چیه)، میتونه هم برای تشخیص پزشکی مورد استفاده قرار بگیره و هم برای تشخیص اسپم. یا مثلاً الگوریتم KNN رو میتونیم برای پیشنهاد کتاب و پیشنهاد فیلم و هم برای کنترل ربات استفاده میکنیم. یا مثلاً از درخت برای شطرنج بازی کردن یا تشخیص تقلب در حساب بانکی استفاده میشه.
خیلی جالبه دیگه. یه سایتی هست به نام Kaggle که مسابقات Data Science اونجا برگزار میشه. یک چیز جالبی که مشاهده کردند اینه که الگوریتم یادگیرنده XGboost (که مبتنی بر درخته) میتونه تعداد زیادی از مسائل رو حل کنه.
یه نکته جالب دیگه اینه که الگوریتمهای یادگیرنده خیلی ساده هستند. خیلی از این الگوریتمها رو میشه در چند صد خط کد پیادهسازی کرد و با این حال مسائل پیچیده و بسیار متفاوتی رو میتونند حل کنند.
اینجا یک سؤال بوجود میاد که «آیا میتونیم یک الگوریتم یادگیرنده داشته باشیم که برای همه مسائل ما جواب تولید کنه؟».
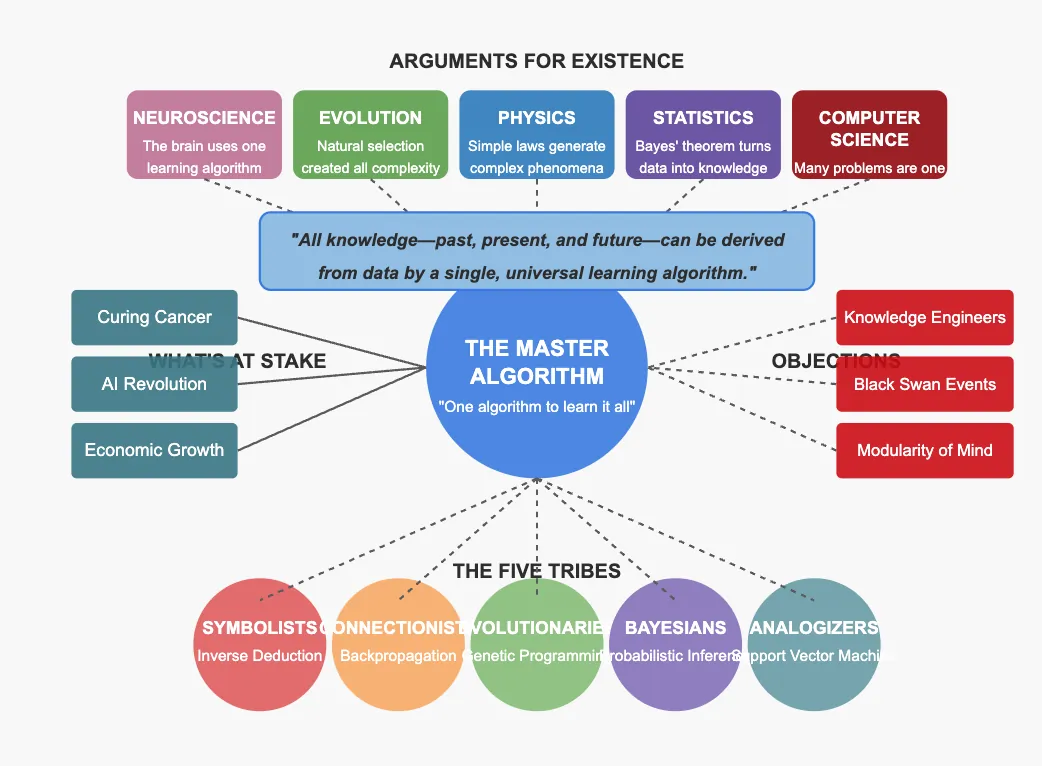
و این گزاره اصلیای هست که نویسنده میخواد بگه بله. میخواد بگه با یک الگوریتم که اسمش رو میگذاره الگوریتم اصلی میشه همه چیز رو در دنیا یاد گرفت. تمام دانش گذشته و حال و آینده رو میشه با یک الگوریتم یادگیرنده اصلی بدست آورد.
اما هنوز همین الگوریتمی نداریم. اما نویسنده میگه اختراع همچین الگوریتمی احتمالاً آخرین دستاورد بشری خواهد بود؛ چون وقتی بوجود بیاد، خودش هر چی نیاز باشه رو اختراع میکنه.
حالا نویسنده ۵ تا استدلال از علوم مختلف میاره که چرا داشتن یک الگوریتم برای یادگیری کافیه؟
استدلالهای وجود داشتن الگوریتم اصلی
استدلال علوم اعصاب (Neuroscience Argument)
تو سال ۲۰۰۰ دانشمندان یه آزمایش جالب روی راسو انجام دادند و تو مقاله Nature هم چاپش کردند. اونها اتصالات عصبی مغزش رو تغییر دادند؛ بهطوری که ورودیهای چشمی به قشر شنوایی (بخشی از مغز که مسئول پردازش صداهاست) و ورودیهای شنیداری به قشر دیداری متصل شدند. قاعدتاً انتظار میره این کار باعث ناتوانی شدید راسو بشه، اما نتیجه کاملاً برعکس بود: قشر شنوایی یاد گرفت که ببیند و قشر دیداری یاد گرفت که بشنود و راسو کاملاً سالم بود. به نظر میاد که بقیه پستانداران هم این شکلی هستند.
حتی خودمون، انسانهایی که مادرزاد نابینا یا ناشنوا هستند، قشر شنوایی و بیناییشون میتونه یاد بگیره که یه کار دیگه بکنه. حتی دیده شده که افراد نابینا میتونند یاد بگیرند که با زبانشون ببینند (مثل خفاش).
همه این مثالها یک معنا میده. این که مغز داره از یک الگوریتم یادگیری یکسان برای همه اینکارها استفاده میکنه. انگار بخشهای مختلف مغز صرفاً یک تکرار از یک الگوریتم هستند و اگر جابهجا بشن، میتونند کار همدیگه رو انجام بدن. انگار فقط ورودیشون فرق داره. یکی به چشم وصله و یک به گوش.
حتی اگر کورتکس مغز رو زیر میکروسکوپ هم بگذاریم، همین رو میبینیم که ساختار سیمکشی مغز در جاهای مختلف خیلی شبیهه. حتی محاسباتی هم که مغز انجام میده، تو جاهای مختلف یکسانه. فقط هم برای آدم نیست؛ به نظر میاد ساختار مغز ما و حیوانهای مختلف خیلی شبیهه. درسته که حجم مغزی ما خیلی بزرگتر حیوونهای دیگه است اما به نظر میاد مبتنی بر اصول یکسانی ساخته شدهایم.
از نظر ژنتیکی هم اگر نگاه کنیم، تعداد اتصالات مغز میلیونها برابر بیشتر از تعداد حروف ژنوم ماست. پس از نظر ژنتیکی امکان نداره که ژنوم بصورت دقیق سیمکشی همه اتصالات مغز رو انجام داده باشه.
حالا راجع به این بخش یک فصل اختصاصی صحبت میکنیم. یک سری دانشمندان کل عمرشون رو صرف این کردند که مغز رو مهندسی معکوس کنند تا بتونند ازش یاد بگیرند. خروجیش هم شده همین Deep Learning که الان میبینید و این یکی از قبایل الگوریتمهای یادگیرنده است که بررسیاش میکنیم.
اگر بخوایم استدلالش رو خلاصه کنیم، میگه که ما با مغزمون که یک الگوریتم بیشتر نیست، میتونیم این همه چیز رو یاد بگیریم، منطقی هست فکر کنیم کامپیوتر هم با یک الگوریتم باید بتونه یاد بگیره. حتی اگر چیزی وجود داشته باشه که بدونیم و مغزمون نتونه یاد بگیره، حتماً بصورت ژنتیکی یاد گرفتیم.
و اینجاست که به استدلال دوم یعنی تکامل میرسیم.
استدلال تکاملی (Argument from Evolution)
تنوع حیات روی کره زمین فقط و فقط محصول یک مکانیزمه: انتخاب طبیعی.
این مکانیزم خیلی شبیه یکی از الگوریتمهای کامپیوتر هست: جستجوی تکراری (iterative search). تو این روش تا جایی که میتونیم راهحل کاندید برای مسئله تولید میکنیم. بعد راهحلهای بهتر رو انتخاب میکنیم و هی تغییر میدیم تا به بهترین راهحل برسیم.
پس تکامل هم یک الگوریتمه. خداوند متعال گونههای متعدد رو خلق نکرده. بلکه الگوریتمی خلق کرده که گونههای مختلف رو تولید کنه. به نظرم هر موجود باهوشی باید به این نتیجه برسه که دستی خلق کردن میلیونها گونه اصلاً کار منطقیای نیست.
انگار طبیعت مثل یه برنامهنویس خیلی باهوشه که داره یه برنامه بزرگ به اسم «زندگی» مینویسه. این برنامه چطور کار میکنه؟ با آزمایش و خطا. طبیعت کلی موجود زنده مختلف (مثل گیاهان، حیوانات، و حتی ما آدما) رو با کدهای ژنتیکی (DNA) میسازه. بعد این موجودات تو محیط زندگیشون آزمایش میشن. اونایی که بهتر میتونن زنده بمونن و بچهدار بشن، کد ژنتیکیشون به نسل بعدی منتقل میشه. اونایی که نمیتونن، کمکم حذف میشن.
پس یه الگوریتم ساده (انتخاب طبیعی) میتونه چیزای خیلی پیچیدهای مثل مغز انسان یا موجودات با تمام پیچیدگیهاشون خلق کنه. پس اگه ما بتونیم این الگوریتم رو تو کامپیوترها شبیهسازی کنیم، شاید بتونیم یه برنامه بسازیم که هر چیزی که قابل یادگیریه رو یاد بگیره.
ولی یه مشکل هست: تکامل تو طبیعت میلیاردها سال طول کشیده و کلی «داده» (تجربه موجودات زنده) مصرف کرده. اگه بخوایم تو کامپیوتر ازش استفاده کنیم، باید یه نسخه خیلی سریعتر و کمدادهتر ازش بسازیم.
پس یه جورایی سؤال Nature vs Nuture (محیط یا ژنتیک) که سالهاست محققان دارند روش کار میکنند یه نسخه کامپیوتری هم داره. تکامل یا مغز؟ دو تا از مهمترین الگوریتمهای یادگیرنده هم روی همین دو تا ایده کار کردند که بهشون میرسیم.
به هر حال، این ایده که تکامل یه الگوریتم یادگیری قویه، یکی از دلایلیه که نویسنده فکر میکنه یه الگوریتم یادگیرنده همهچیز میتونه وجود داشته باشه.
استدلال از فیزیک (Argument from physics)
استدلالی که از فیزیک میاره اینه که به نظر میاد هر چیزی که ما تجربه میکنیم، حاصل یک سری قانون فیزیکی ساده است. با اینکه جهان خیلی پیچیده به نظر میرسد (مثل کوه ها، رودخانهها، ابرها)، همه چیز در نهایت از چند قانون ساده فیزیک پیروی میکند که میتوانند پدیدههای بسیار پیچیدهای مثل حیات یا حتی تکامل را به وجود بیاورند.
انگار جهان پر از نظم و الگو است، و یک الگوریتم ساده میتواند آنها را پیدا کند. درباره مجموعه مندلبرو یا بازی حیات (Game of life) از جان کانوی یه سرچ بکنید. میبینید که چطور قوانین بسیار ساده میتونند اشکال بسیار پیچیده رو خلق کنند.
در طبیعت، سیستمهای خیلی متفاوت (مثل امواج آب، حرکت سیارات، یا حتی رفتار حیوانات) گاهی رفتارهای مشابهی دارند. مثلاً معادلهای که امواج را توضیح میدهد بعداً به شکلهای دیگه تو علوم دیگه هم به کار میره.
یه استدلال جالب دیگه هم میاره. میگه که اساس دنیا بهینهسازی طبق قوانین فیزیک و شیمی هست. بهینهسازی یا Optimization تعریفش اینه که یک تابعی داریم و میخوایم نقطه Min یا Maxاش رو پیدا کنیم یعنی به اجازه چه مقادیر ورودیای خروجی تابع حداقل میشه. بسیار هم مسئله سختی هست.
تو اقتصاد داریم بهینهسازی انجام میدیم، هر آدم و هم شرکتی میخواد سود خودش رو بیشینه کنه. پس یک سری راهحل بهینه با تکنولوژیهای موجود پیدا میکنیم.
تکنولوژی موجود خودش یک مسئله بهینهسازی هست. فناوری تو چهارچوب محدودیتهای فیزیکی و زیستشناسی است. فناوریهایی که ما میسازیم، نمیتوانند قوانین بنیادین فیزیک یا محدودیتهای زیستی (مانند تواناییهای بدن انسان یا موجودات زنده) را نقض کنند.
دستگاههای پزشکی باید با فیزیولوژی بدن انسان کار کنند و به بافتهای زنده آسیب نزنند.
از طرفی زیستشناسی هم در چارچوب قوانین فیزیک عمل میکند و یه مسئله بهینهسازی رو حل میکنه که با فیزیک محدود شده. مثلاً، تکامل موجودات زنده را طوری بهینه کرده که با قوانینی مثل جاذبه یا دما سازگار باشند.
پس انگار ما داریم کلاً تو اکثر علوم مسئله بهینهسازی حل میکنیم و فکر میکنیم علوم مختلف داریم.
استدلال آماری (Argument from Statistics)
استدلال آماری میگه یه فرمول ساده به اسم قضیه بیز میتونه پایه همه یادگیریها باشه. این قضیه دادههای جدید رو میگیره و باورها (فرضیهها) رو آپدیت میکنه تا به دانش برسه.
قضیه بیز با یک سری فرضیه راجع به دنیا شروع میکنه. حالا اون فرضیههایی که با داده سازگارترند میشن محتملتر و اون فرضیههای که با داده ناسازگاری بیشتری دارند، کمتر محتمل میشن. همین.
مثلاً میخوای بدونی یه ایمیل اسپمه یا نه. فرضیههات ایناست: «این ایمیل اسپمه» یا «این ایمیل اسپم نیست». حالا یه داده جدید میبینی، مثلاً میبینی تو متن ایمیل کلمه «جایزه» هست. قضیه بیز بهت میگه چطور احتمال هر فرضیه رو با این داده جدید آپدیت کنی.
پس کلاً تعریفمون از یادگیری متفاوت میشه. میگیم «یادگیری یعنی آپدیت کردن باورها».
بر اساس آمار بیزین، تنها راهی که میگه داده رو به دانش تبدیل کرد همین یادگیری بیزین هست.
هر چی دانش پیچیدهتر میشه، بیز میتونه پیچیدگی مدل رو افزایش بده و باهاش کنار بیاد. یه فصل حالا راجع به این مکتب بیزین صحبت میکنیم.
ولی در کل این حرف که با یک الگوریتم میشه همه یادگیری رو انجام داد، خیلی حرف بزرگی هست و اگر هم تا حالا محدودیتی وجود داشته که بیز چه چیزی رو نمیتونه یاد بگیره ازش خبر نداریم.
استدلال علوم کامپیوتر (Argument from Computer Science)
اگر الگوریتم پاس کرده باشید احتمالاً کلاس P و NP و اینها به گوشتون خورده. یک روش هست برای دستهبندی مسائل و الگوریتمهای حوزه کامپیوتر:
کلاس P مسائلی هست که میشه تو زمان چندجملهای و کوتاه حل کرد. جوابش رو هم میشه سریع چک کرد. مثل مرتب سازی لیست یا پیدا کردن کوتاه ترین مسیر در گراف.
کلاس NP مسائلی هستند که لزوماً تو زمان چندجملهای نمیشه حل کرد ولی جوابش رو میشه در زمان چندجملهای و کوتاه چک کرد. مثلاً سودوکو حلش خیلی سخته. اما من اگر سودوکو رو حل کنم و جوابش رو بهتون بدم، شما سریع میتونی چک کنی که درست حل کردم یا نه.
کلاس NP-Complete سختترین مسائل کلاس NP هستند. نشون داده شده که تمام مسائل NP-Complete رو میشه به NP تبدیل کرد. بعد جالبه. اگر شما بتونی یه دونه از این مسائل رو حل کنی، همهاش رو حل کردی چون همش رو میشه به هم تبدیل کرد. خیلی حرف بزرگی هست. من اون زمان تو درس الگوریتم به سادگی از این عبارت گذشتم. الان که این آقا دوباره دست گذاشته روش میفهمم چقدر مهمه.
پس انگار بخش بزرگی از چیزهایی که تو الگوریتم داریم حل میکنیم همگی یکی هستند. پس مسئله فروشنده دورهگرد و سودوکو، مسئله زمانبندی هواپیما، مسئله فشردهسازی دیسک و حتی بازی تتریس. همه اینها انگار یکی هستند. فقط شکلشون عوض شده. اثبات دقیق ریاضی داره ها که این مسائل یکی هستند.
کی حدس میزد که این همه الگوریتم همشون یکی باشند؟
جدای از این قضیه این که ما همین الان از یک کامپیوتر برای همه کارهامون استفاده میکنیم عجیبه. ماشین تورینگ هم نشان میدهد یک ماشین واحد میتواند هر مسئله قابلحل منطقی را حل کند. این ایده به مستر الگوریتم (Master Algorithm) تشبیه شده، با این تفاوت که ماشین تورینگ برای استنتاج (deduction) است، درحالیکه مستر الگوریتم برای استقرا (induction) و یادگیری از دادهها طراحی شده است.
انتقادات به الگوریتم اصلی
اینجا نویسنده میاد به برخی انتقادات حول این ایده الگوریتم اصلی پاسخ میده.
چالش اول: مهندسی دانش در برابر یادگیری ماشین
اولین انتقاد از طرف کسایی میاد که به مهندسی دانش اعتقاد دارن، مثل ماروین مینسکی، یکی از پیشگامای هوش مصنوعی و استاد دانشگاه MIT. این گروه میگن: «یادگیری ماشین نمیتونه دانش واقعی و عمیق تولید کنه. دانش باید توسط آدمای متخصص، مثل دانشمندان، به صورت دستی وارد کامپیوتر بشه. دادههای بزرگ فقط یه جور فریبن» اونا فکر میکنن یادگیری ماشین فقط برای کارهای ساده، مثل فیلتر کردن ایمیلهای اسپم، خوبه، ولی برای چیزای پیچیده، مثل فهم دنیای واقعی، باید متخصصان بشینن و قواعد رو یکییکی بنویسن.
مینسکی این انتقاد رو یه قدم جلوتر میبره. اون تو کتابش «جامعه ذهن» میگه ذهن انسان یه الگوریتم واحد نیست، بلکه یه عالمه مکانیسم مختلفه که با هم کار میکنن. به قول دومینگوس، انگار مینسکی میگه: «ذهن فقط یه عالمه چیز جورواجوره!» اون باور داره که هوش مصنوعی باید از کلی روش مختلف ساخته بشه، نه یه الگوریتم.
چالش دوم: انتقادات نوام چامسکی
دومین انتقاد از نوام چامسکی، زبانشناس معروف، میاد. چامسکی میگه: «یادگیری زبان فقط از دادهها ممکن نیست.» اون یه نظریهای داره به اسم «فقر محرک». چامسکی میگه که کودکان در معرض دادههای زبانی محدودی قرار دارند که نمیتواند بهتنهایی برای یادگیری کامل دستور زبان کافی باشد. اما کودکان میتونند دستور زبان پیچیدهای را در مدت زمان کوتاهی فرا گیرند. این امر نشان میدهد که باید ساختارهای زبانی بهصورت ذاتی در ذهن انسان وجود داشته باشد. پس توانایی زبان باید ژنتیکی باشه، چیزی که از تکامل بهمون رسیده. چامسکی اصلاً یادگیری آماری رو قبول نداره و میگه این روشا خیلی سادهلوحانهان و مثل رفتارگرایی قدیمین که فقط به ارتباط بین چیزا نگاه میکنن.
نویسنده خیلی زحمت کشیده و برای هر کدوم از اینها کلی استدلال آورده. ولی فکر میکنم الان بعد گذشت ۱۰ سال با ظهور LLMها مشخص شده که رویکرد نویسنده منطقیتر بوده. یعنی هم نیازی به مهندسی دانش نبوده و تونستیم بدون مهندسی دانش این حجم دانش رو به LLM یاد بدیم و هم انتقادات نوآم چامسکی زیرسؤال رفته.
چالش سوم: رویدادهای غیرقابلپیشبینی (قوی سیاه)
سومین انتقاد از نسیم طالب، نویسنده کتاب «قوی سیاه»، میاد. طالب میگه بعضی اتفاقات، مثل بحران مالی 2008، غیرقابلپیشبینین. مثلاً اگه تا حالا فقط قوهای سفید دیده باشی، فکر میکنی قوهای سیاه وجود ندارن. به نظرش هیچ الگوریتمی نمیتونه این جور اتفاقات نادر رو پیشبینی کنه، چون تو دادههای قبلی نیستن.
جواب نویسنده چیه؟
اینجا نویسنده میگه طالب زیادی بدبینه! اتفاقاتی مثل بحران 2008 در واقع قابلپیشبینی بودن و خیلیها هم پیشبینیشون کردن. الگوریتمهای یادگیری ماشین میتونن حتی اتفاقات نادر رو پیشبینی کنن. حالا جلوتر میبینیم یادگیری بیزین چندان مشکلی که نسیم طالب میگه رو نداره و به تبع اون الگوریتم اصلی هم برای یادگیری هر چیزی که قابل دانستنه طراحی شده.
چالش چهارم: تنوع الگوریتمهای یادگیری ماشین
آخرین انتقاد از خود متخصصای یادگیری ماشین میاد. اونا میگن: «تو دنیای واقعی، هر مشکلی یه الگوریتم خاص لازم داره. مثلاً یه الگوریتم برای تشخیص تصویر خوبه، یکی دیگه برای پیشبینی سهام. چطور یه الگوریتم واحد میتونه جای همه اینا رو بگیره؟» اونا میگن ما همیشه باید کلی الگوریتم مختلف رو امتحان کنیم تا بهترینش رو پیدا کنیم.
جواب نویسنده چیه؟
دومینگوس قبول داره که الگوریتمهای مختلف نقاط قوت خودشون رو دارن، ولی میگه اگه بتونیم بفهمیم هر الگوریتم چی رو خوب انجام میده و این نقاط قوت رو با هم ترکیب کنیم، میتونیم یه الگوریتم واحد بسازیم. به جای اینکه صدتا مدل مختلف رو امتحان کنیم، میتونیم فقط نسخههای مختلف یه الگوریتم اصلی رو تست کنیم. اون میگه هدف کتابش همینه: پیدا کردن راهی برای ترکیب بهترین ویژگیهای الگوریتمهای موجود.
قبایل مختلف یادگیری ماشین
حالا به هر حال هنوز الان که نتونستیم یک الگوریتم واحد داشته باشیم که همه کار رو انجام بده. اما به بیان نویسنده پنج تا قبیله مهم تو یادگیری ماشین داریم که ترکیب این قبایل شاید بتونه الگوریتم اصلی رو بسازه:
| قبیله | مسئلهٔ کلیدی | منبع الهام | الگوریتم شاخص |
|---|---|---|---|
| نمادگرایان (Symbolists) | استدلال منطقی از داده | منطق و فلسفهٔ علم | استقراء معکوس، درخت تصمیم، Rule Learners |
| اتصالیون (Connectionists) | یادگیری وزن نورونها | علوم اعصاب | پسانتشار خطا، شبکههای عمیق |
| تکاملگرایان (Evolutionaries) | تکامل ساختار مدل | زیستشناسی تکاملی | برنامهسازی ژنتیکی، الگوریتم ژنتیک |
| بیزیها (Bayesians) | استدلال با عدمقطعیت | آمار و احتمال | استنباط بیزی، شبکههای بیزی |
| قیاسیون/شباهتگراها (Analogizers) | یافتن شباهت نمونهها | - | SVM، k‑NN |
| تو فصل بعد از اولی شروع میکنیم و جلو میریم ولی فعلاً اگر بخوایم بصورت خلاصه بگیم: |
- نمادگرایان (Symbolists): دانش بهصورت قواعد منطقی نمایش داده میشود و یادگیری یعنی کشف یا تعمیم این قواعد. الگوریتم یادگیریشون استقراء معکوس (Inverse Deduction) هست و در عمل درخت تصمیم بوجود میاد.
- اتصالیون (Connectionists): یادگیری یعنی بهروزرسانی وزنِ اتصالات نورونی. همین که پارامترهای مدل آپدیت بشن یعنی ما یاد گرفتیم. این قبیله خیلی هم موفق بوده و Deep Learning و همین LLMها هم دستاورد این قبیله است.
- تکاملگرایان (Evolutionaries): طبیعت با انتخاب طبیعی میآموزد؛ کامپیوتر هم باید بتواند.
- بیزیها (Bayesians): تمام دانش، باورهای احتمالی است که با داده بهروز میشود.
- قیاسیون/شباهتگراها (Analogizers): حل مسئله با یافتن نمونههای مشابه.
نویسنده میگه که «الگوریتم اصلی (مادر)» باید عناصر برتر هر قبیله را ترکیب کند. ایده است برای خودش دیگه. به نظرم میاد لزوماً با ترکیب بهترین الگوریتمها، الگوریتم بهتر حاصل نمیشه. اما شاید هم شد.
به هر حال گوش دادن به حرفهای یک دانشمند این حوزه برام جذاب بود. از فصل بعد به سراغ الگوریتمهای Symbolic میریم و امیدوارم که براتون مفید بوده باشه.