سلام. امیر پورمندم و امروز شنبه ۶ مرداد ۱۴۰۳ هست. هوا به شدت گرمه. تو قسمت قبل راجع به چند تا از چالشهایی که موقع کارکردن با مدلهای زبانی بزرگ پیش میاد صحبت کردیم. تو این قسمت میخوام بخش دوم این چالشها رو بگم.
علت این که دو قسمت صحبت میکنم اینه که به اندازه کافی به مزایای LLMها پرداخته شده و خیلیها راجع بهش حرف زدند. شما الان هر شبکه اجتماعیای رو باز کنید، کلی آدم راجع به مزایای این ابزارها صحبت میکنند. چیزی که کمتر راجع بهش صحبت میشه ضعفها هست.
همین هم هست که وقتی میخوایم با این مدلها محصول بسازیم؛ چون هیچ درکی از ضعفهاش نداریم و صرفاً چند تا کلیپ از قسمت خوب ماجرا رو دیدیم، دچار مشکل میشیم. البته OpenAI وظیفهاش هست که اغراق کنه و خودش رو خوب نشون بده. ولی من به شخصه تعهدی نسبت به OpenAI ندارم :)
پس تو این قسمت هم طبق روال قسمت قبل راجع به ضعفهای مدلهای زبانی صحبت میکنیم و کمکم بحث رو جمع میکنیم.
شنیدن اپیزود
همه اپیزودهای این پادکست تو کانال کست باکس منتشر میشه و البته میتونید از جاهای دیگه هم بشنوید.اینجا هم میتونید فایل صوتی این قسمت رو گوش بدید:
مقدمه
خلاصه قسمت قبل این بود که این مدلها هم تو طول ورودی و هم تو طول خروجی محدودیت دارند و اینطوری نیست که هر چی خواستید بهشون بدید و حتی میدونیم اگر هم مدل ورودیاش خیلی بزرگ باشه، باز هم ممکنه کیفیتاش افت پیدا کنه و به نظر میاد یه Trade-off بین طول ورودی و کیفیت جواب داشته باشیم.
بعد راجع به این صحبت کردیم که LLM از دنیای واقعی ما هیچ اطلاعاتی نداره. مثلاً نمیدونه که امروز اینجا تو یزد دمای هوا ۴۵ درجه سانتیگراده. یا نمیدونه که فردا به همین علت گرما تعطیل شد. LLM صرفاً اطلاعات زمانی رو داره که آموزش دیده. راهکارش هم استفاده از API هست که بیایم اطلاعات رو بهش بدیم. یا این که بعضی وقتها اطلاعاتش راجع به یک موضوعی کمه بیایم با روشهای موسوم به RAG بهش داده بیشتر بدیم.
در مورد توهم مدل حرف زدیم و گفتیم که چندان کاریش نمیشه کرد. و امنیت مدل و این که برای ساخت محصول در زمینه LLM بهتره چرخ رو از اول اختراع نکنیم.
اینها خلاصه اپیزود قبله. بریم این قسمت رو شروع کنیم:
نداشتن حافظه (Memoryless) و آموزش ندیدن لحظهای
مدلهای LLM فعلیای که داریم چیزی به نام حافظه ندارند. یعنی قرار نیست که وقتی بهشون درخواست میدید، یادشون بمونه که قبلاً چی گفتید.
اینجا سوالی که پیش میاد اینه که چطوری این همه چت بات با LLM داریم. مشخصاً تو چتباتها حافظه المان مهمی هست. سوال قشنگیه.
بحث اینه که ما دستمون از لحاظ خود مدل بسته است. یعنی همه مدلهایی که داریم صرفاً یک طول ورودی میگیرند و بر مبنای ورودیای که گرفتند خروجی میدن. اصلاً چیزی به نام حافظه داخلشون تعریف نشده.
ولی میشه یه حقه زد. میشه تو هر بار صدا زدن این مدلها، کل history تا الان چت رو بهش بدیم و بگیم که این سوال جوابهایی هست که تا الان کاربر داشته و حالا این سوال جدیدش هست. حالا جواب بده.
دقیقاً همین کار رو میکنند و طول ورودی هر مدلی هم محدوده میبینیم وقتی تو ChatGPT یا Claude تعداد پیامهامون بالا بره، چتمون رو میبنده!
حالا چند تا راهکار هم داره. بعضیها میگن هیستوری چت رو Cut کنیم. یعنی مثلاً ۵ تا چت آخر رو نگاه داریم. یا اصلاً بر اساس تعداد توکن Cut کنیم. بعضیها میگن به اندازهای که تو ورودی مدل جا میشه، به مدل بدیم و ازش بخوایم متن رو خلاصه کنیم و خلاصهاش رو به جای اون متن طولانی استفاده کنیم.
ولی به نظر میاد که این راهحل بیشتر از جنس «مسکّن» هست تا راهحل واقعی.
اگر بخوایم به طور کلی نگاه کنیم مدلهای هوشمصنوعی دو تا فاز دارند: یکی فاز آموزش و دوم فاز استنتاج (Training vs Inference).
مسئله اینه که مدلهایی که معمولاً تو محیط عملیاتی هستند، دارند دائما با دادههای جدید آموزش میبینند. مثلاً مدل پیشنهاد دهنده ایسنتاگرام تشخیص میده که شما امروز و این ساعت دلتون میخواد آموزش آشپزی ببینید و سریع پیشنهادهاش رو آپدیت میکنه. به این تو ادبیات یادگیری ماشین، یادگیری مداوم (Continual Learning) میگن.
ولی مدلهای زبانی بزرگ اینطور نیستند. شما هر بار که دارید با یه LLM صحبت میکنید، هیچ اطلاعاتی از صحبتهای قبلیای که باهاش داشتید نداره! هیچ آموزشی ندیده.
برای همین نیازه که کل چتهای قبلی رو بچپونیم داخل ورودی! و این باعث میشه برای خیلی از کاربردها نامناسب بشن. یعنی به این شکل به سختی میشه مدل رو برای یکی شخصیسازی کرد. هر بار با مدل صحبت میکنید، مثال «روز از نو، روزی از نو» هست. مدل هیچی یاد نمیگیره.
خیلی وقتها، فرآیند یادگیری مدل تو هوش مصنوعی مترادف هست با تغییر وزن تو مدل. یعنی وقتی پارامترهای مدل در جهتی که ما میخوایم تغییر میکنند، بهش میگیم یادگیری. ولی وزنهای LLM کاملاً فیکس هستند.
شاید در آینده به این سمت بریم که به ازای هر کاربر یه مدل Customize شده LLM داشته باشیم ولی فعلاً انقدر هزینه آموزش یک مدل هم زیاده که واقعاً نمیشه به تعداد کاربرها مدل Train کرد.
البته تو پرانتر بگم که مدلهای LLM همین الانش هم همواره در حال آموزش هستند ولی انقدر هزینه و زمان آموزش بالاست که مثلاً چندین هفته یا چندین ماه طول میکشه یک مدل LLM بدست بیاد. بعدشم باید برن بررسی کنند و ببینند، این مدلی که بدست اومده چقدر مناسب هست. شاید بگید که مدل رو کوچیک کنیم حل میشه! ولی مسئله اینه که بسیاری از ویژگیهای خیلی خوب مدلهای زبانی به همراه «بزرگشدن» ظهور (Emerge) کرده و اگر کوچیکشون کنیم، خیلی از اون ویژگیها از دست میرن.
پس عملاً دو تا ضعف رو گفتیم، یکی این که مدل حافظه نداره و دوم این که هیچی یاد نمیگیره (Inference is single-pass).
حالا میشه بیشتر به این قضیه فکر کرد که این ضعف کجاها میتونه به تجربه کاربر ضربه بزنه؟
This is What Limits Current LLMs
سوگیری (Bias) و انصاف (Fairness)
قبلا گفتیم که مدلها از دادههای عمومی مثل اینترنت تغذیه میشن. اینطوری هم نیست که همه مطالب اینترنت انتخاب بشه و معمولاً یک نمونهای انتخاب میشه. حالا همین سواله که چطوری انتخاب میشه؟ احتمالاً از موتورهای جستجوگر استفاده میکنند و نتایج آخر موتورهای جستجو شاید حذف بشن.
و بعد از کلی فیلتر میگذره تا به داده آموزش برسه. مثلاً یه فیلتر میتونه حذف مطالب بر اساس وجود برخی کلمات نامناسب در اونها باشه. همین خودش مسئلهسازه چون فیلتر کردن یعنی حذف نظرات برخی گروهها بصورت سیستماتیک.
حتی اگر این هم نباشه، اینترنت خودش ذاتاً سوگیری داره. هر شبکه اجتماعیای قواعد خودش رو داره که همه نمیتونند توش فعالیت کنند. در ثانی اگر دقیقتر نگاه کنیم توزیع سنی، جنسی، مذهبی و خیلی از دستهبندیهای دیگه تو اینترنت اصلاً برابر نیست. مثلاً حجم مطالبی که نسل جوون تولید میکنند خیلی بیشتر از نسل قدیمیتره. پس قاعدتاً مدل بیشتر با عقاید نسل جدید هماهنگ میشه (و نه نسل قدیم).
بنابراین LLM هم که از این دادهها یاد میگیره، سوگیری رو هم یاد میگیره! یاد میگیره سیاهپوست بودن رو با جرم و جنایت مرتبط بدونه (چون تو خیلی جاها این واژهها در کنار هم اومدن - حالا چه راجع به دفاع از سیاهپوستها چه نقدشون) و هر چی هم با روشهای Alignment سعی کنیم این عامل رو از بین ببریم، یه جاهایی خودش رو نشون میده. (روشهای Alignment همون چیزی بود که تحت عنوان ورود به دانشگاه تو قسمت نهم راجع بهش صحبت کردم).
مسئله اینه ما خودمون سالها سوگیری داشتیم و داریم و توی اکثر متونی که میخونیم (از جمله این متن) سوگیری هست. چطوری از LLM انتظار داریم که این رو نداشته باشه؟
سوگیری هم فقط برای مدلهای زبانی بزرگ مطرح نمیشه و کلاً برای خیلی از مجموعه دادگان ما مطرح میشه. حتی تو فرآیند مصاحبهها اگر نگاه کنید این سوگیری وجود داره. خیلی وقتها اون مصاحبهگر بر مبنای ویژگیهای جنسیتی و مذهبی و زیبایی و ویژگیهایی که بعضاً ربطی به اون کار ندارند، فلانی رو حذف میکنه. حالا شما اگر بیای یه دیتاست از این درست کنی و سعی کنی که تشخیص بدی کدوم کاندیداها مناسبترند، دوباره این بایاس به مدل هم منتقل میشه.
حتی جالب این که نشون داده شده حتی اگر تو این موارد سن و جنسیت و ویژگیهای که نمیخوایم مدل بر اساسشون تصمیم بگیره رو از دیتاستمون حذف کنیم، باز مدل خودش سعی میکنه تشخیص بده جنسیت طرف چیه و بر همون مبنا تصمیمگیریش بایاس میشه.
کلاً مسئله اینه که ما خودمون به شدت تو تصمیمگیری و سایر موارد بایاس هستیم ولی میخوایم مدلهایی رو با دادههای خودمون (!) درست کنیم که اینطور نباشند!
کنترلپذیری خروجی (JSON Output)
یکی از چیزهایی که به شخصه خیلی باهاش سر و کار داشتم، کنترلکردن خروجی LLMهاست. مثلاً یه چیزی که برای استفاده از مدل خیلی لازم میشه اینه که مدل خروجی JSON بده. یه فرمت خاصی از خروجی هست که تو برنامهنویسی خیلی رایجه.
انقدر این مورد مهم بود که خود OpenAI اومد یه ورودی به APIاش اضافه کرد و گفت اگر خروجی JSON میخوای بگو. من سعی میکنم حتماً خروجی JSON بهت بدم. کار هم میکنه. خیلی هم عالیه.
اما نه همیشه! هر چقدر هم پرامپت خوب بهش بدیم، شاید ۹۸ یا ۹۹ درصد جوری که ما میخوایم کار میکنه و خروجی رو میده. تو بقیه موارد خودمون باید کلی مکانیزم retry و چیزهای دیگه بهش اضافه کنیم که اون یکی دو درصد رو پوشش بدیم.
به نظر هم نمیاد این مشکل به سادگی قابل حل باشه چون احتمالاً به توهم ربط پیدا میکنه!
این چیزی که راجع بهش صحبت میکنم آخرین مدلهای ChatGPT مثل GPT-4o هست که انقدر مشکل داره. دیگه شما در نظر بگیرید که مدلی که خودمون Fine-tune کرده باشیم دیگه چیه.
تفسیرپذیری مدلهای زبانی (Interpretability, Explainability)
تفسیرپذیری مسئلهای نیست که مختص مدلهای زبانی بزرگ باشه. کلاً مدلهای Deep این چالش براشون مطرح میشه.
مسئله اینه که ما خودمون وقت میگذاریم، به روشهای آموزش مدلها و کلاً مفهوم یادگیری فکر میکنیم. بعد کلی روش پیشنهاد میدیم و کد یکیاش رو پیادهسازی میکنیم و یه مدل آموزش میدیم. حالا جالب این که خروجیای که بدست میاد رو نمیفهمیم چطوری رفتار میکنه!
البته دقیقاً میدونم مکانیزم ریاضی پشتش چیه و چطوری آموزشش دادیم. میتونیم حتی اگر حوصلهاش رو داشته باشیم خودمون دستی با توجه به وزنهای مدل، خروجی دقیق رو بدست بیاریم. ولی باز نمیفهمیمش.
بگذارید با مثال توضیح بدم. فرض کنید که میخوایم مدلی آموزش بدیم که شتر و اسب رو بتونه تشخیص بده. وقتی مدل یاد گرفت که تشخیص بده واقعاً بر اساس هزاران عامل یا صدها هزار عامل تشخیص میده. ولی ما انتظار داریم که بتونیم خروجی مدل رو خیلی سادهتر بفهمیم. مهمتر از اون میخوایم بدونیم که چرا مدل این رو اسب تشخیص داده نه شتر.
حالا با روشهای مختلف میان مدل رو تفسیرپذیر میکنند. مثلاً من تو تز ارشدم عکس زیر که گربه تشخیص داده شده رو تفسیرپذیر کردم. یعنی تونستم توضیح بدم که مدل حدوداً بر چه مبنایی تشخیص داده. اون ناحیههایی که تو تشخیصش مهمتر بوده قرمزتر نشون داده شده.
 ولی این تفسیرپذیری به سادگی برای همه مدلهای عمیق قابل اعمال نیستند.
ولی این تفسیرپذیری به سادگی برای همه مدلهای عمیق قابل اعمال نیستند.
با ادبیات تابع هم میشه به این مورد نگاه کرد. ما روشهایی درست کردیم که تو فضای توابع موجود بگردیم و یه تابع رو خروجی بدیم اسمش رو بگذارید GPT-4. حالا این تابع رو داریم. این تابع، هزاران ورودی و هزاران خروجی داره و میلیاردها وزن. ولی انقدر پیچیده است که نمیفهمیم چیه. اینطوری عملاً نمیتونیم بگیم که فلان لایه داره دقیقاً چیکار میکنند. چون تو هر لایه نگاه میکنی یه سری ضرب و تقسیم و کارهای ریاضی ساده است.
چطوری از این ضرب و تقسیمها مدل توانایی این رو پیدا میکنه که بتونه مثل ما حرف بزنه؟
برنامهریزی و استنتاج (Planning and reasoning)
مدلهای زبانی بزرگ تو حفظ کردن خیلی از ما جلوترن. اصلاً قابل مقایسه نیستیم باهاشون. شما هر آزمون حفظیای رو به LLM بدید، کمتر انسانی میتونه باهاش رقابت کنه.
اما اگر استنتاج هم به این قسمت اضافه بشه، کمکم ضعف LLM مشخص میشه. سختی کار هم اینجا هست که خیلی وقتها نمیتونیم بفهمیم کاری که مدل داره انجام میده اینه که چیزی که قبلاً حفظ کرده رو جواب میده یا این که واقعاً استدلال میکنه.
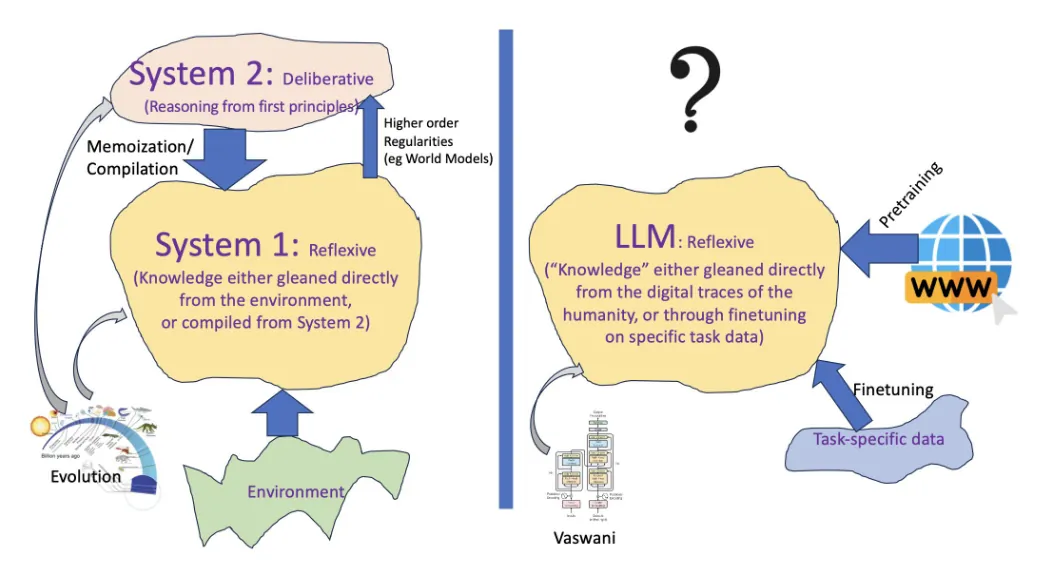
برداشت من تا حالا این بوده که LLMها بیشتر از این که توانایی استدلال داشته باشند، توانایی بازیابی نسبتاً قوی دارند. یعنی خیلیوقتها یه سری الگوها رو میتونند شبیهسازی کنند و مثل اون الگو متن تولید کنند اما خیلی متفاوته با اون روشی که ما هنگامی که «سیستم ۲مون» فعال میشه، استدلال میکنیم.
حتی تو کار سادهای مثل توانایی بازیابی هم کاملاً دقیق نیستند؛ یعنی شما ۱۰۰ تا جمله بهش بدید، بگید عیناً همینها رو بده، بعضاً این کار رو هم نمیتونه انجام بده و میبینیم که یه چیز دیگه برای خودش خروجی میده.
تو برنامهریزی هم همینه. یعنی جاهای مختلف که ازش تست گرفته شده دیدند که خروجیاش از آدم خیلی ضعیفتره و این به نظرم خوبه.
اتفاقاً یه جایی ضعیف باشه که ما هم بتونیم خودی نشون بدیم وگرنه اگر تو همه زمینهها قوی بود که به «هوش مصنوعی کل» یا AGI دست یافته بودیم و الان هممون بیکار شده بودیم.
موخره
بحثهای دیگهای هم هست که میشه راجع بهش صحبت کرد. از جمله این که LLMها به شدت وابسته به پرامپت ورودیشون هستند یا این که خیلی وقتها اگر بخوای بهش دانش جدید یاد بدی، اون چیزهایی که قبلاً یاد گرفته رو هم فراموش میکنه (Catastrophic Forgetting) یا سرعتشون که الان به شدت کنده؛ چون توکن به توکن خروجی میده. ولی به نظرم تا همین جای بحث برای ما کافیه.
امیدوارم که براتون مفید بوده باشه.
منابع
- On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
- Extracting Concepts from GPT-4 | OpenAI
- [2403.04121] Can Large Language Models Reason and Plan?
- [2307.06435] A Comprehensive Overview of Large Language Models (Page 33-34)
- [2303.18223] A Survey of Large Language Models (Page 62-63)
- [2307.10169] Challenges and Applications of Large Language Models (Page 1-33)
- A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
- What can LLMs never do? - by Rohit Krishnan